
Elo ELI5'd
Understanding Elo ratings
Last week I came across this silly website called EloEverything (via July links on Astral Codex Ten).
EloEverything displays two items & asks which one you rank higher. For example:

Apples and oranges, obviously, but New Zealand, I guess?
Anyway, here are the top-5 items on EloEverything as I’m writing this post:

How are these items ranked? Not surprisingly given the website’s name, the items are ranked by their Elo score.
While I had heard of Elo scores, I never really knew exactly what they meant. Since knowledge is apparently the #1 thing, I thought I’d try to understand how Elo scores work.
Here’s what I learned.
Elo ratings in a nutshell
While Elo scores can be used to build silly websites (including a famous social network), they are best known in chess. In fact, the Elo rating system was devised by a Hungarian-born American physicist Arpad Elo (Wikipedia) for calculating the relative strength of chess players.
The beauty of the system is that Elo ratings can be interpreted in terms of probabilities. That is, if you know the Elo ratings of two players, you can calculate the expected score in a game between them as follows:
In this formula, A and B denote the two different players, R stands for the Elo rating, and E is the expected score in the game (we count a win as 1, a draw as 1/2, and a loss as 0).1 For example, if player A’s Elo rating is 400 points higher, the expected score for player A is 10/11, or roughly 0.91.
This probabilistic feature of the Elo system differs a lot from usual ranking systems in sports. For example, here are the final standings in the Premier League (2022/23 season):
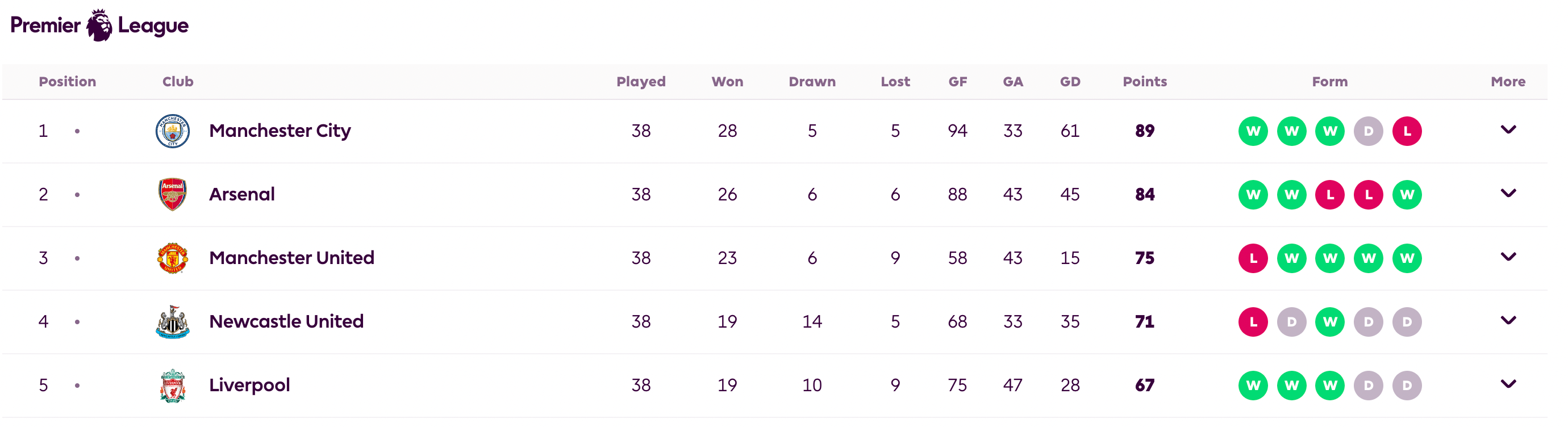
In (European) football a.k.a. soccer, you get 3 points for a win, 1 point for a draw, and 0 points for a loss. At the end of a season, you count the total number of points, and the team with the highest number of points wins. That’s it. You cannot use the difference in points between Manchester City and Arsenal to estimate the probability that Man City will beat the Gunners in an upcoming match.
Now, Elo scores are based on a model with a bunch of simplifying assumptions. Hence, we should not expect the predicted score to be 100% accurate. However, at least as an approximation, the Elo rating system forecasts the outcomes of real-world chess games surprisingly well.
After each game, the Elo ratings of the participants are updated using the following formula:
Here, S denotes the actual score, and K is a positive number. The International Chess Federation (FIDE), for example, uses a value of K = 40 for new players, and a value of K = 10 for players with an Elo rating above 2,400.
This updating rule is really intuitive. We can think of the difference, S - E, as a metric of how “surprising” the outcome of the game is; the more surprising the result, the more is the Elo rating updated. For example, if player A is predicted to win with certainty (E = 1), and she actually wins (S = 1), her rating stays unchanged. However, if the player is predicted to lose with certainty (E = 0) but then wins (S = 1), that’s very surprising, and her score is increased by K points. (The formula is very similar to Kalman-filtering equations in that respect.)
Numerical example
For more intuition, we can consider a numerical example.
Consider a chess match between Player A and Player B. Let's say Player A has an Elo rating of 2,000 and Player B has an Elo rating of 1,800. The expected score for each player can be calculated using the formula provided above:
So, Player A is expected to get a score of 76%, while Player B is expected to get a score of 24%
Now, let's assume that the players have played a game and Player B won, which was a surprising outcome. Assuming that the K-factor is 30 (a common value for experienced players), the new ratings become
So, Player A's rating drops to 1977, and Player B's rating increases to 1823 after the game. This reflects the surprising outcome, as the win by Player B results in a larger adjustment due to the lower initial expectation of winning.
A simple model
If you’re like me, you may now be wondering where exactly these formulas come from. In this section, I will present a simple model of chess that yields (a version of) the Elo rating system.
Expected score
Suppose that each player has a certain level of chess-playing ability, A. However, actual performance in a game, P, equals the player’s ability plus some noise, ε. You can think of this noise as capturing the idea that “some days are better than others.” So, for a player i, her actual performance is
Think of ability, A, as a fixed number for each player. For simplicity, let’s assume that noise is normally and independently distributed across all games and players:
Now consider a game between two players, player i and player j. Player i wins against player j if and only if player i performs better. (Note that there are no draws in this model: Either player i wins, or player j wins.)
We can now calculate the probability that player i wins:
Now, given our assumptions on normality above,
Therefore,
where Φ denotes the standard normal CDF.
Now, the units of “chess-playing ability”, A, are arbitrary, and we can choose them in any way we like. The Elo system uses the following normalization: If player i’s ability is 400 units greater, then player i should be 10x more likely to win. In other words, if
then the probability of i winning should be 10/11 (i.e. 10x higher then the probability of j winning—which is 1/11).
This choice of units yields an equation that we can use to pin down σ:
So now, if we know the abilities of the two players, we can readily calculate the probability that one of them wins:
We are left with only one loose end. In this simple model, draws are not modeled. However, we can perform some mental gymnastics and call the “probability that player i wins” as the “expected score for player i,” with the convention that a draw yields a score of 1/2. (It turns out that this approximation works quite well in practice.) If we also say “rating” instead of “ability,” we obtain a formula for the expected score that is very similar to what we saw at the top of the post:
Side note on logistic distribution
We did not quite get the exact same formula for the expected score, i.e.
For that, we would need to assume that instead of being normally distributed, chess-playing ability follows the Gumbel distribution. The difference between two i.i.d. Gumbel-distributed random variables (with the same scale parameter) then follows the logistic distribution. If you impose the same normalization—that a difference of 400 in underlying ability yields a 10x difference in the win probability—and use the logistic distribution, you will get the exact same formula. Left as an exercise for the reader, as they say.
As an alternative, we could approximate the standard normal cdf with a logistic cdf, for example, by matching the first two moments (see here for a discussion):
Using this approximation on the formula obtained above, we can calculate that
which is very close to the standard Elo rating formula.
Why would one choose the Gumbel distribution over the normal distribution for chess-playing ability? It appears that the key reason is empirical: The Gumpel distribution simply yields more accurate predictions for game outcomes.
Updating rule
OK, so now we understand where the formula
comes from. It results from specifying an underlying distribution for chess-playing ability and using that distribution to predict the outcome of a game.
To estimate this unobserved chess-playing ability, we use data on game outcomes. We already saw that Elo ratings are updated by the following updating rule:
That brings us to the next obvious question: Why is this specific rule used in the Elo rating system?
The first thing to note is that while this rule is intuitive, it’s unlikely to be optimal. For example, Bayesian updating suggests that, if player A wins, we should update more strongly when (i) A has a short track record (as we are relatively uncertain of A’s ability); or (ii) B has a long track record (as we are relatively certain of B‘s ability). However, the Elo updating rule does not take such information into account (see here for a deeper discussion).
Nevertheless, this updating rule works well in practice, and we can provide a heuristic argument for why: The Elo updating rule implements a version of stochastic gradient descent. That’s a pretty surprising connection as stochastic gradient descent forms the basis for much of modern machine learning. (What follows draws heavily from the exposition in Wikipedia, based on my interpretation and some additions.)
Here’s the argument. Suppose you want to estimate the chess-playing ability of a bunch of players using a large dataset of games. The way we would typically address this problem, in the world of classical statistics, would be to write down a data-generating process and deduce the likelihood function. Then, we would estimate parameters by maximizing the likelihood function.
While we could do that in theory, in practice that would be very difficult and computationally intensive, and the end result would certainly not give us simple updating formulas. What we could do instead is to write down the likelihood function for a single game, calculate the gradient of this function, and use that gradient to update the estimates. It turns out that this simplified algorithm gives us precisely the Elo updating rule.
Let’s see how that works. First, using the Bernoulli distribution, the likelihood function for a single game is
(Note that E depends on the ratings R through the expected score formula.) The single data point is S which—as we abstract from draws—can be either 0 or 1. We take logs to obtain the log-likelihood function for easier algebra:
With some algebra, we can calculate the derivative of the log-likelihood function to be
To improve the log-likelihood, we should move in the direction of the gradient, i.e., we should update
where η is the step size of the gradient-descent algorithm. Substituting the expression for the partial derivative, we have
That’s precisely the Elo updating rule.
Concluding thoughts
This turned out to be a much longer post than I anticipated (much more math, too!).
Anyway, delving deep into the Elo system has been fascinating. The Elo system is a brilliant tool for quantifying and predicting relative performance. Despite its apparent simplicity, it elegantly encapsulates pretty complex statistical concepts (such as stochastic gradient descent and latent variables), bringing them together into an easy-to-understand framework.
Of course, all models are simplifications of reality and come with inherent limitations. It’s an inexact science. But regardless of whether you’re estimating the outcome of a chess match or comparing New Zeleand to an emergency department, the Elo rating system offers a surprisingly nuanced tool.
Unfortunately, Substack does not (yet) support subscripts, so my explanation of the notation is a bit confusing. Sorry.