


Are AI coding tools slowing you down?
Revisiting the data from METR's productivity study

Do AI coding tools increase your productivity?
If you’d asked me this a few weeks ago, I’d have immediately replied, “Oh yes, totally.”
Then METR, an AI research organization, released this striking study:
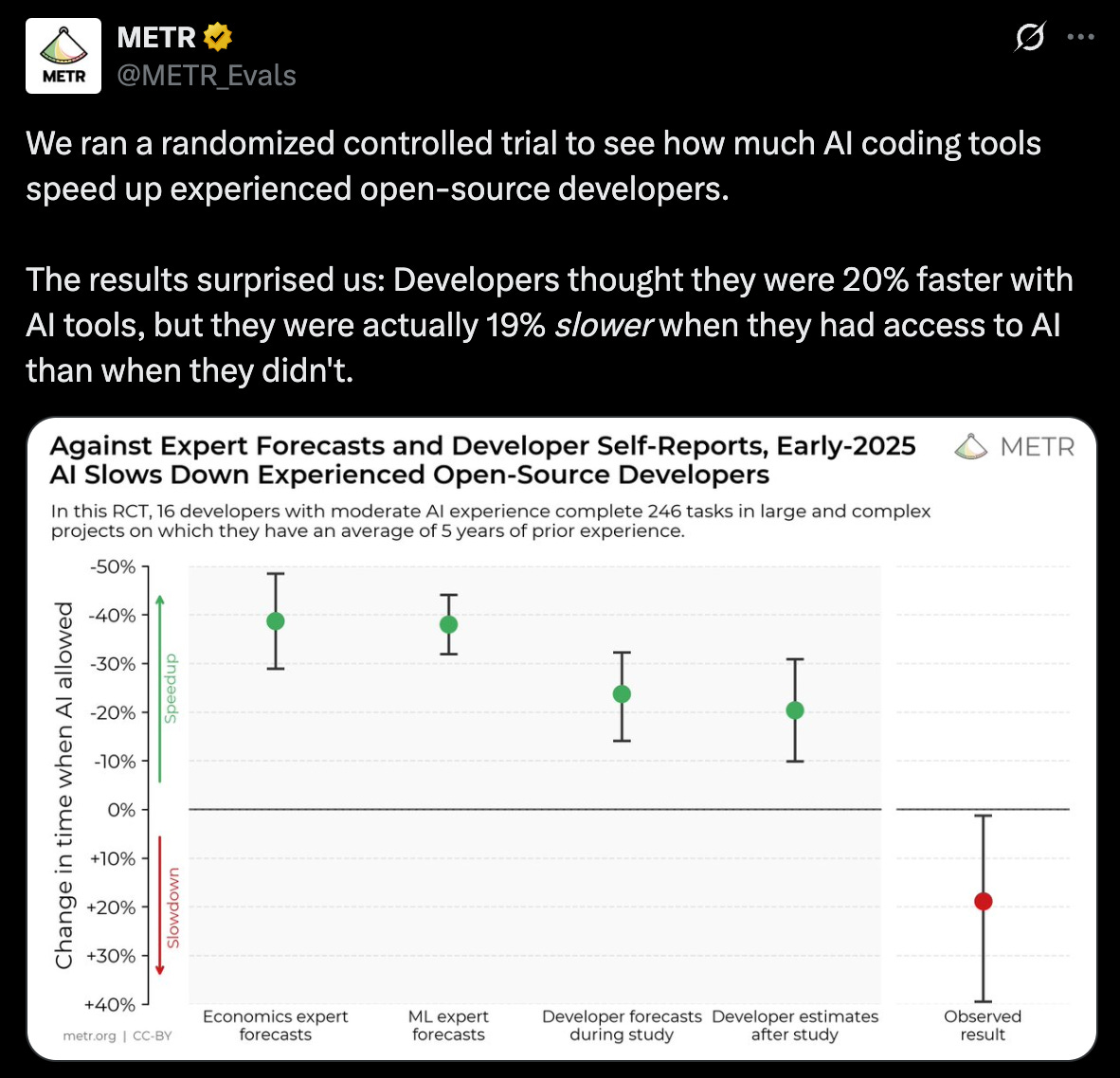
METR conducted an experiment to measure how AI coding tools (primarily Cursor) affect the productivity of software developers. Surprisingly, AI coding tools reduced productivity.
Much has already been written about this study. Zvi, as always, provides an excellent overview.1 I won’t rehash those internet debates here, except to mention that most critiques have focused on external validity (e.g., how relevant are results drawn from experienced open-source contributors to the broader developer community?).
In this post, I’ll instead kick the tires of METR’s data analysis: Are their results robust? Do the statistical analyses hold up? Is the study internally valid?
My main takeaway, after examining the data: METR’s productivity study appears robust. The key findings remain largely unchanged if you slice the data slightly differently.
This post wouldn’t have been possible without the outstanding efforts of the METR team. First, to state the obvious, the study is extremely thoughtful and relevant. It also takes courage to publish such contentious findings. Additionally, the team has open-sourced the data and code and generously answered my various questions. Most people get defensive in situations like that. In contrast, the METR folks I’ve spoken with seemed very open and genuinely committed to truth-seeking. Hats off to you, METR. This is how science should be done.
All the results below were generated using this Jupyter notebook. If you spot any bugs, please let me know in the comments.
I. Why I was skeptical
I was quite skeptical when I first came across this study.
To begin with, I use AI coding tools daily, and they feel very helpful. For example, I recently vibe coded my personal website from scratch, and I couldn’t have done that without Cursor. I’m hardly alone in this sentiment: Cursor is arguably the fastest growing SaaS product ever, with $500M in annual recurring revenue. That’s a strong signal that Cursor enhances developer productivity.
On top of that, when you examine the headline result, the confidence bounds just barely exclude zero:
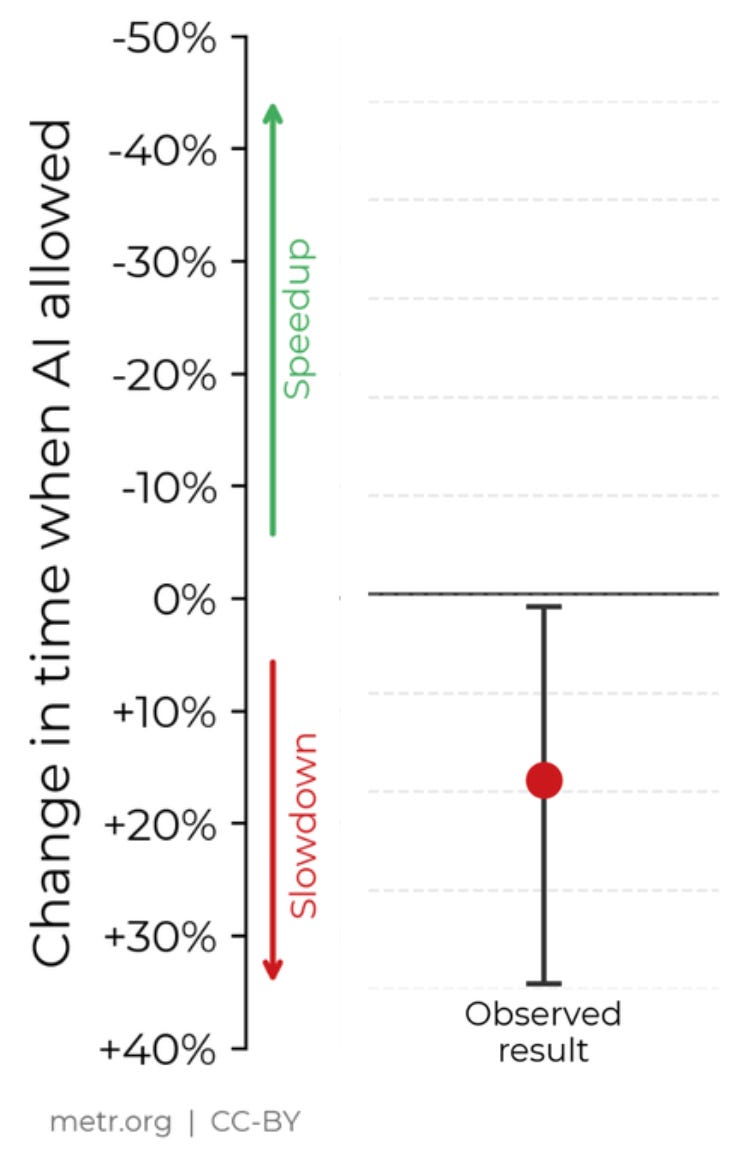
Given what we’ve learned from the Replication Crisis, it’s natural to look at a graph like this and go, “Hmm, these standard errors seem suspiciously small!” The METR study also only included 16 developers. Can you really do reliable statistics with a sample size of N = 16?
This brings us to the first tire-kicking exercise.
II. Is statistical uncertainty correctly estimated?
In the METR study, randomization was done at the issue level (i.e., each issue represented a known bug or feature needing implementation); the experiment had N = 246 issues. However, issue-level randomization may leave some residual correlation at the developer level if, for example, some developers are consistently faster than others. The original analysis employed homoskedastic standard errors, which could underestimate statistical uncertainty if such correlation exists.2
To investigate, I re-analyzed the data using a simple regression model:
Here, Y is the time (in minutes) developer i spent resolving issue j. Since the study randomized at the issue level, the treatment variable T only has an issue index j.
My approach differs somewhat from METR’s original specification:
METR used log(time) as the dependent variable, whereas I used absolute time in minutes. Both approaches have merits, but modeling the dependent variable in levels is slightly more interpretable (e.g., “30 minutes slower” vs. “20% slower”);
METR didn’t include developer fixed effects in their baseline regression. However, including these fixed effects creates a cleaner “within-developer” comparison, directly answering how much a given developer slows down with or without AI coding tools. Omitting fixed effects mixes within- and between-developer variation, which could be misleading;
METR study additionally included the predicted time a task would take without AI tools, primarily to increase statistical power. While reasonable, additional controls can introduce researcher degrees of freedom, which I aimed to avoid;
My regression used “time to first completion” (i.e., time until the first pull request) instead of “time to full completion” as in the METR study. Some data required for full completion time were missing, and I preferred to avoid imputations.
To address potential within-developer correlation, I employed two standard approaches to estimate statistical uncertainty:
Clustered standard errors (clustered at the developer level);
Hierarchical bootstrap (first sampling developers with replacement, then issues within developers).
Given that there are only 16 developers, clustered standard errors may suffer from small sample-size problems, potentially making the hierarchical bootstrap more reliable.
Here are the results (error bars represent 95% confidence intervals):
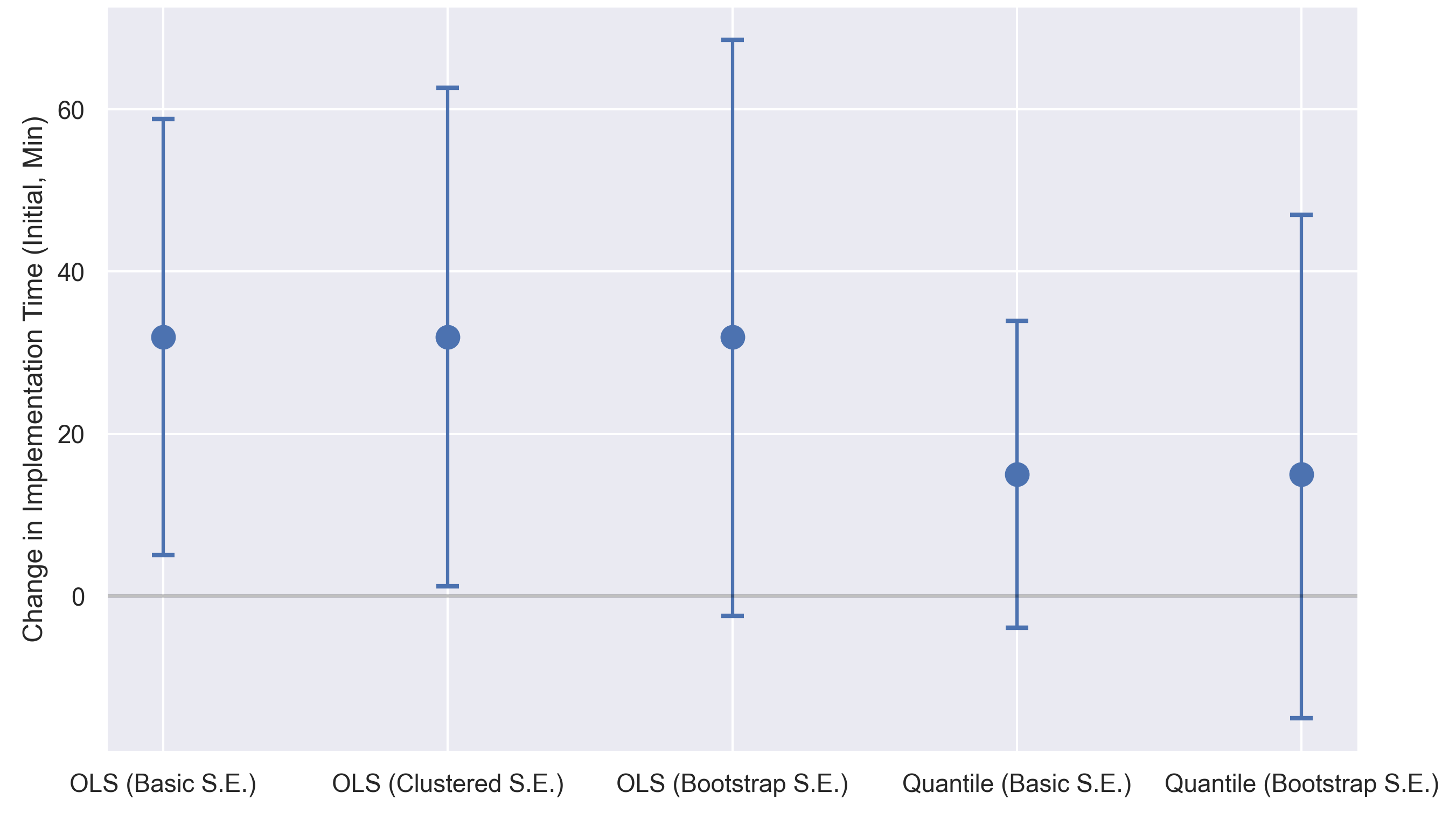
According to these estimates, AI coding tools increase issue completion time by around 30 minutes on average.3 For reference, the average issue in the study took around 100 minutes to solve.
Bootstrap standard errors, though larger, aren’t drastically bigger than the basic standard errors used in METR’s headline regression. Thus, while bootstrap standard errors might better capture statistical uncertainty, within-developer correlation doesn’t appear to substantially affect the results.4˒5
On the other hand, using bootstrap standard errors, the negative productivity impact is no longer statistically significant.
As an additional robustness check, I re-estimated the regression model using median quantile regression, shown in the last two estimates above. With quantile regression, the point estimate still suggests reduced productivity (15-minute increase in issue completion time). However, the effect is no longer statistically significant, irrespective of what standard errors are used.
Still, across all analyses, the 95% confidence intervals consistently rule out large positive productivity effects.
To sum up:
The result that “AI coding tools decrease productivity in a statistically significant way” appears somewhat fragile;
The finding that “AI coding tools do not increase productivity” is robust.
III. Is the randomization valid?
The standard errors seem to be mostly fine.
My next concern was the randomization itself. Maybe the randomization was imbalanced, with issues assigned to the “AI Allowed” group being inherently more challenging? Such an imbalance could easily explain the apparent productivity slowdown.
To test this possibility, I conducted balance tests to see if observable characteristics were comparable between the treatment (“AI Allowed”) and control (“No AI“) groups. Here are the main results:
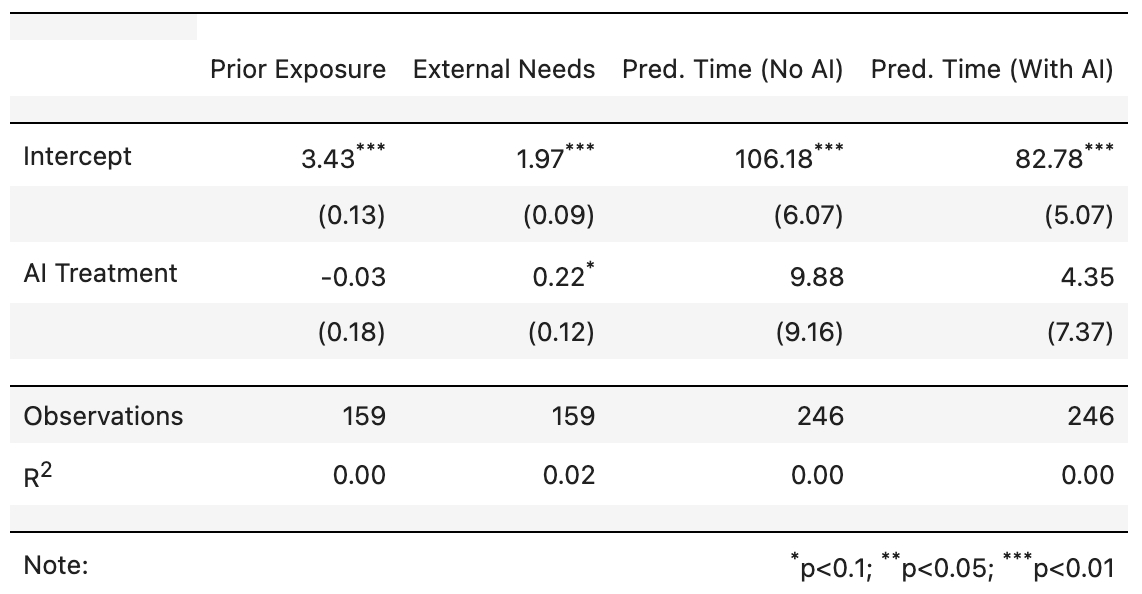
In this table:
“Prior Exposure” indicates a developer’s familiarity with the task type on a 1–5 scale;
“External Needs” rates whether external resources (such as docs) are necessary, on a scale of 1–3;
The final two columns represent developers’ predicted completion times, both without and with AI.
With the possible exception of “External Needs” (marginally significant at p < 0.10), all balance tests passed. However, the “External Needs” and prediction columns suggest that the issues in the “AI Allowed” condition were slightly more difficult. These differences, however, are too small to explain the observed large productivity differences.
Overall, the randomization appears sound.6
IV. Developers over-estimated the usefulness of Cursor
Finally, I looked at how accurately developers predicted the impact of AI coding tools.
Developers consistently overestimated the benefits provided by AI coding tools. The graph below illustrates results from a regression similar to the one described in Section II but with “forecast errors” (predicted implementation time minus actual time) as the dependent variable:
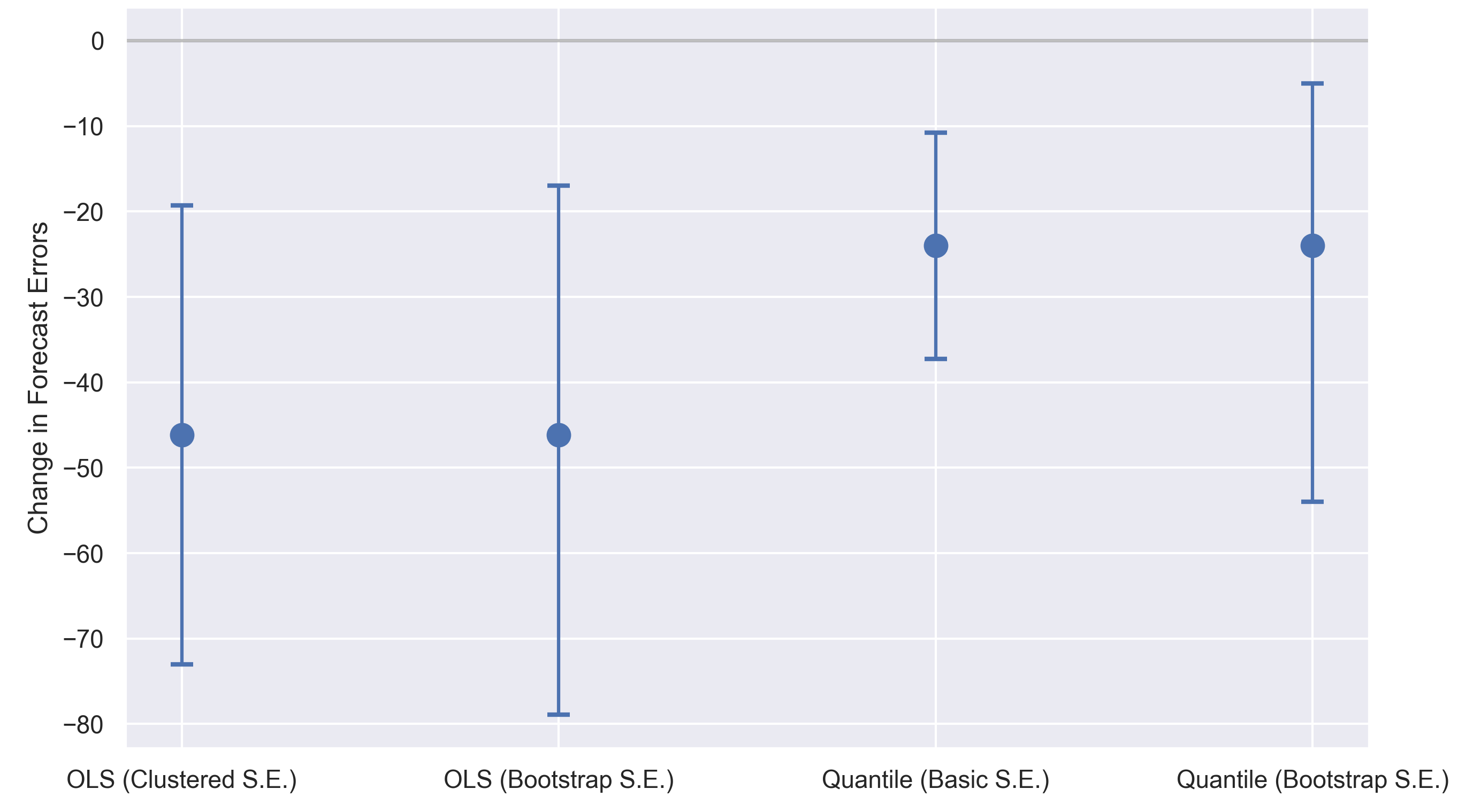
A negative forecast error indicates over-optimism about completion time—meaning the actual implementation took longer than expected. Developers showed greater over-optimism in the “AI Allowed” condition. This result was consistent across both the mean (least-squares regression) and the median (quantile regression) estimates, irrespective of what standard errors were used.
V. Takeaways and some meta
Here are my main takeaways:
The central finding—that AI coding tools didn’t lead to substantially higher productivity—appears highly robust;
Whether AI coding tools actively decreased productivity is less clear and seems much more debatable. Maybe yes, maybe no;
Developers consistently overestimated the positive impact of AI tools on their productivity.
I’ll conclude with a few broader reflections.
First, you shouldn’t rely too heavily on any single study. As Alex Tabarrok says, “trust literatures, not papers!” Although that’s a cliché, more research is needed before drawing strong conclusions.
Personally, based on my past work, I’d assign this study a Bayes factor of around 0.5 (i.e., moderate evidence against substantial productivity gains in this specific context). However, my prior expectation is that most interventions fail. So, I’m not hugely surprised that Cursor, at least in certain scenarios, didn’t boost productivity.
Second, I think that the METR team deserves praise for an exemplary job. They were candid about what could be driving the apparent slowdown. They open-sourced the code and data. They also kindly answered numerous questions when I reached out to them. Doing high-quality research is incredibly hard, and no single study is ever the final word. Future research will refine, and might even overturn, some conclusions of the METR study—but that’s a feature, not a bug. The courage to share results openly, especially when they’re so surprising, is precisely what drives science forward.
So, are AI coding tools slowing you down?
Maybe not. But they’re probably not making you a 10x engineer, either.
The updated version of the paper (as of July 31, 2025) uses heteroskedasticity-robust standard errors for the headline regression. However, these standard errors also do not adjust for potential within-developer correlation.
30 minutes correspond to a roughly 30% increase in implementation time, consistent with the “ratio estimator” results in Figure 13 of the METR report.
Consistent with this finding, most of the developer fixed effects weren’t statistically significant. The updated version of the METR study (as of July 31, 2025) also estimates standard errors with different estimators (Figure 15), with similar results to mine.
The lack of strong within-developer correlation also assuages some of the concerns about low statistical power. In the METR study, the average issue took around 100 minutes to solve with a standard deviation also close to 100 minutes. Using this power calculator with the default parameter values and E = 0.35 (hypothesized effect size) and S = 1.00 (standard deviation) yields a required sample size of N = 256 issues for 80% power, close enough to N = 246 in the paper. Assuming a within-developer correlation of ρ = 0.05 (roughly consistent with the data) and m = 15 issues per developer, the study is well-powered to detect a Cohen’s d of around 0.47, i.e., a moderate effect size.